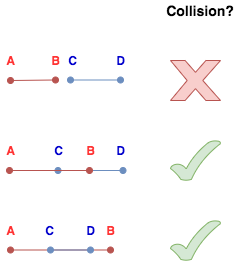
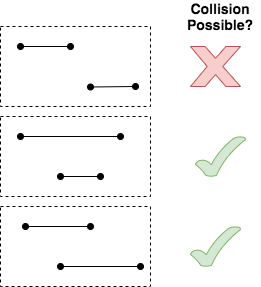
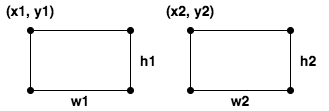
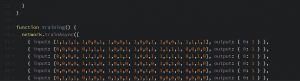
Many teachers suffer from a cognitive bias known as the “Curse of Knowledge.” When you’ve mastered something, many aspects of that topic feel basic or intuitive. Especially, as time passes and you forget what it was like to initially struggle with a concept. To combat this, many of us take off our teacher hats from time to time and don our learner hats. We can do that in many ways. To that end, a few years ago I enrolled in a program called OMSCS: Georgia Tech’s Online Masters of Computer Science. This summer I took my last classes and graduated from the program. At the end of any valuable experience, it is worthwhile to reflect on it to extract the lessons you can carry with you.
Going into the OMSCS experience, there were some things I knew I would get out of it: a deeper understanding of many areas of computer science, the chance to take on the role of a learner in my field, and a chance to collaborate and learn alongside other working professionals. I also ended up not just thinking about the content taught to me but the way the professors delivered their courses in an online format. I didn’t expect the online aspect of it to be so relevant in my own teaching but here we are.
Here are a few lessons I learned beyond the content of my courses:
- The urge to procrastinate is strong! With less face-to-face time with teachers, there feels like a little less accountability. Something that helps is breaking big tasks down into smaller ones. Having more deadlines or milestones can actually reduce stress as it leads to not putting off work longer.
- Input = Output What you put into a class correlates to how much you get out of it. It can be tempting to just put in the minimal effort and check off the list of things you are required to do to get the grade but I find I got way more out of the classes where I looked into the supplemental resources provided, read beyond just the assigned chapters and tinkered with concepts.
- Going off the point above: It’s okay to just survive! I did not (wasn’t able to) go above and beyond in every class, only the ones I felt compelled to do so. Especially now, there’s so much on our plates that just checking off the to-do list and making it to the next week is more than admirable
- Over-communication > under-communication
Yes, getting tons of emails is annoying and I’ve changed my settings on various platforms to reduce the number of notifications I receive. But, getting too much information has been an easier problem for me to deal with than getting too little information. I’d rather repeat myself multiple times and in different ways at the risk of sounding like a broken record than leave some behind and confused. With background stressors, there can be hidden factors that cause our attention to fade or to forget something we just heard. Having information in an email, on a class website, in a pre-recorded video, and repeated live is not just covering all our bases but maximizing the chance that it’s received by all. As a student, don’t be afraid to follow-up on an email a teacher hasn’t responded to after a few days: many can get lost in the ever-growing mountain we call our inbox. I know I’m guilty. - Relationships > Content
Teaching and learning can be a fun, academic puzzle to solve. How do I express this idea? How do I explain it in a way others can understand? How can I design it in a way to guide someone to learn it themselves? But at the end of the day, the people doing the teaching and the people doing the learning are human beings with a lifetime of experiences, fears, joys, interests, biases, etc… Connecting with the people in our space (physical or virtual) is the real challenge of a school no matter your role. I remember the teammates I worked with on group projects more than the lectures on the principles of software engineering, artificial intelligence, databases, and security. I value the peer reviews, TA feedback and the time the professor admitted they were wrong in a forum post and showed me even experts in a field get mixed up sometimes - Fast, simple feedback loops drastically improve learning
One of my favorite but most challenging classes was Artificial Intelligence. I learned more in that class than any other not only because of that challenge but due to the speed and quality of feedback. The professor set up a way for us to submit the code we wrote and have it tested and our results were given back to us quickly. So I could create an AI to battle another one and my score was based on its performance and when it did poorly I could attempt to figure out why and make improvements. In the classes I teach involving computer programming, I have a similar setup for some tasks but for many types of work, this isn’t possible. A lesson I take from this is to try to give and get as much feedback as you can! Peer review, asking for more feedback when you don’t get enough, and iterating on your work are all good ideas. - Finding a good balance of control is important
Sometimes it’s nice to just get straightforward tasks and directions and do the work. Other times, it’s better to get a chance to be creative and come up with our own tasks. I think any good learning experience or course should have a mix of varying degrees of teacher and learner control. I try to structure my courses by giving specific tasks to learners with very explicit directions and feedback at first to build core skills then opening it up to allow students to take the skills they built in the directions they want to take them and chart their own courses of exploration. When I set out to learn a new skill, I start by following step by step tutorials and reading books or guides and then planning personal projects using the knowledge gained from that first stage of learning.
I have avoided talking about my specific content area too much since I think these lessons apply regardless of if you’re teaching/learning computer science or anything else. But I would like to speak a little to one of my favorite sub-fields of CS: game design. I have made so many connections between designing good games and crafting effective lessons and courses. You have to understand the person playing your game (or student learning your topic) and give them the appropriate level of challenge: too easy and they get bored, too complex before they’re ready and they get frustrated. We want to keep them in the zone where they’re just brushing up against the boundary of their current level of skill to push them to make it to the next level. We have to make it interactive and get them to get “in character” and take on the role of superhero, mathematician, problem solver, computer scientist, race car driver, whatever. It’s an iterative process. We try out our ideas, get feedback, and improve on it next time. There will be many failures as we navigate the world of virtual learning but that’s exciting. Because each “failure” is an opportunity to learn and to grow.